
FourthBrain recently hosted an event on Transfer Learning with MLflow led by Feifei Wang, Senior Data Scientist at Databricks. If you’d like to follow along with the hands-on demo, feel free to download the slides and notebooks from the following GitHub repo.
The event sparked these questions that we'll explore in today's post:
- What is Databricks and what problem does it solve?
- What are the expectations of an outstanding Data Scientist/ML Engineer today?
- Where can I go to learn more about FourthBrain, Databricks, and future events like this?
What is Databricks and what problem does it solve?
The Databricks Lakehouse Platform combines the best elements of data lakes and data warehouses to deliver the reliability, strong governance, and performance of data warehouses with the openness, flexibility, and machine learning support of data lakes.
This unified approach simplifies your modern data stack by eliminating the data silos that traditionally separate and complicate data engineering, analytics, BI, data science and machine learning. It’s built on open source and open standards to maximize flexibility. Lastly, its common approach to data management, security and governance helps you operate more efficiently and innovate faster.
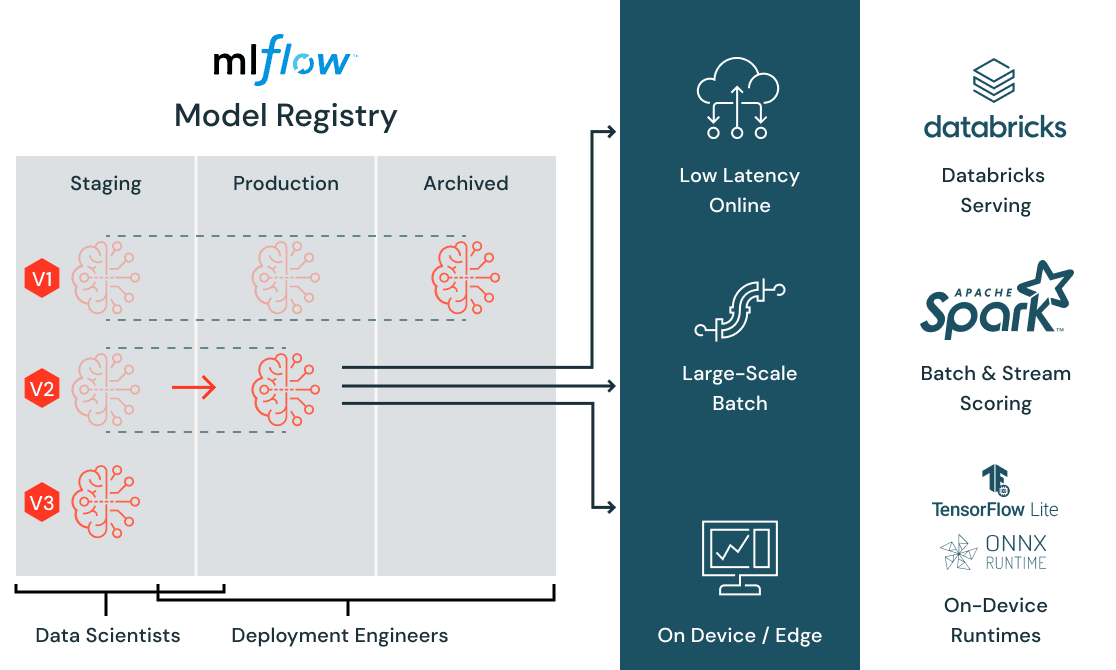
As a Machine Learning Engineer, Databricks Machine Learning empowers ML teams to prepare and process data, streamlines cross-team collaboration and standardizes the full ML lifecycle from experimentation to production enabling you to deploy models at scale and with low latency.

Databricks model registry and model deployment features (Source)
If you’re interested in learning more about notable alternatives to Databricks in the Data Science and Machine Learning Platform space, I’d recommend you check out:
- Dataiku
- H20.ai
- Alteryx
In the live demo, Feifei walked through a very common use case that Data Scientists and ML Engineers face today where she wanted to perform image classification but didn’t have enough data (either due to time, resource, or other constraints) to train a reliable model; enter: Transfer Learning.
Transfer Learning is a machine learning method where a model developed for a general task is reused as the starting point for a different model trained on a second task. It is a popular technique in deep learning tasks for computer vision and natural language processing and can often result in better performance with less training data.

Transfer Learning (source)
Lisa Torrey and Jude Shavlik in their chapter on transfer learning describe three possible benefits to look for when using transfer learning:
- Higher start. The initial skill on the source model is higher than expected.
- Higher slope. The rate of improvement of skill during training of the source model is steeper
- Higher asymptote. The converged skill of the trained model is better

Three ways in which transfer might improve learning (source)
Feifei used the Tensorflow Transfer Learning tutorial as a starting point and the general steps involved in applying transfer learning in computer vision or natural language processing are as follows:
- Download a pre-trained model for a representative task (i.e. image classification, object detection, sentiment analysis, audio classification, etc.). In this demo, the pre-trained model comes from Tensorflow Hub but you can also find pre-trained models at the following sites:
- Model Zoo
- PyTorch Hub
- HuggingFace Models
- Papers with Code
- Prepare data and create a train, validation, and test set
- Define model architecture with a pre-trained model base and set necessary training parameters
- Train the model and perform gradual fine-tuning, as needed.
Now Feifei used the MobileNetV2 model pre-trained on ImageNet which Google released in 2019 along with this paper but the real focus of this hands-on demo was to introduce MLflow and how it can be used to manage the ML lifecycle, including experimentation, reproducibility, deployment, and a central model registry. In the first notebook, she demonstrated how to use the autolog() feature to automate the logging of key training/validation metrics, model training parameters, and artifacts and in the second notebook, she used the manual logging features to kick off a grid search for hyperparameter optimization and again capturing key metrics, model parameters, and other artifacts.

One line change to Jupyter Notebook to ensure reproducibility

Custom logging in MLflow for hyperparameter optimization

MLflow UI with nested runs after custom hyperparameter training loop
As you can see, MLflow provides a significant improvement over manual experiment tracking methods such as experimentation logs and/or markdown files in a repo, CSV files, or other manual logging methods. Feifei’s presentation demonstrates that it is trivial to incorporate robust experimentation and reproducibility measures into your existing workflow.
If you’re interested in learning more about MLflow, I would suggest starting with the Quickstart documentation.
What are the expectations of an outstanding Data Scientist/ML Engineer today?
To wrap up, Feifei discussed the importance of following software engineering best practices in ML workflows and referenced the “Hidden Technical Debt in Machine Learning Systems” paper published by researchers at Google in 2015 which had the popular graphic seen below highlighting the fact that most of the code in ML systems goes beyond the actual code used to train a machine learning model.

{kind=link}
{kind=link}
A small fraction of real-world ML systems are composed of ML code
At FourthBrain, we believe that for an engineer to be able to contribute to high-performing AI product teams they must be able to leverage real-world data to build, package, and deploy state-of-the-art ML models as containerized web applications in cloud-based production environments. MLflow is an industry-standard open-source library to manage the ML lifecycle, including experimentation, reproducibility, deployment, and a central model registry but it is just the tip of the iceberg in terms of software tools and best practices that enable ML engineers to do their best work.
In each phase of the ML project lifecycle, our goal as part of the MLOps and Machine Learning Engineering curriculum is to empower students to gain a better understanding of the big picture in ML systems and develop the necessary skill sets to not only develop ML models that are impactful to their business but to do so in a way that leverages software engineering best practices for the code, data, and other supporting artifacts in a project. For a good reference on the MLOps tools landscape, Neptune.ai compiled this visualization.
{kind=link}

{kind=link}
Where can I go to learn more about FourthBrain, Databricks, and future events like this?
If you are interested in learning more about the Machine Learning programs at FourthBrain, check out our website for the next cohort start dates and follow us on LinkedIn to be notified of future events like this one. Lastly, if you would like to get hands-on with Databricks and follow along with Feifei’s live demo, feel free to try their free community edition.